LLM Papers
Surveys
-
Information Retrieval
- 15 August 2023: Large Language Models for Information Retrieval: A Survey
-
Factuality
-
X-of-Thought
-
Software Engineering
- 19 November 2023: A Survey on Language Models for Code
- 11 October 2023: Large Language Models for Software Engineering: Survey and Open Problems
-
Agents
- 20 November 2023: Igniting Language Intelligence: The Hitchhiker’s GuideFrom Chain-of-Thought Reasoning to Language Agents
- 27 September 2023: Cognitive Architectures for Language Agents
- 19 September 2023: The Rise and Potential of Large Language Model Based Agents: A Survey
- 7 September 2023: A Survey on Large Language Model based Autonomous Agents
-
Autonomous Driving
- 2 November 2023: A Survey of Large Language Models for Autonomous Driving
-
Hallucinations
-
Audio Processing
- 22 September 2023: Sparks of Large Audio Models: A Survey and Outlook
-
Temporal Data
-
Medicine
X-of-Thought
7 November 2023: Everything Of Thoughts : Defying The Law Of Penrose Triangle For Thought Generation
The latest breakthrough in the field of Chain of Thought (CoT) is the XoT (eXtended Chain of Thought) approach. This method uses pretrained reinforcement learning combined with Monte Carlo tree search to integrate knowledge from external domains into thought generation. The Monte Carlo search explores potential thought structures, then creates a policy and value network for these thoughts (a policy network selects actions to take from a given state or thought, while a value network assesses the quality of a given state and whether it corresponds to a thought that can solve the problem). It then deduces the best possible thought trajectory for solving the problem. This proposed method is highly efficient and requires few calls to Large Language Models (LLMs), needing only a single call with the thought trajectory calculated by the Monte Carlo search.
17 May 2023: Tree of Thoughts: Deliberate Problem Solving with Large Language Models

“Tree of Thoughts” (ToT) approach, a problem-solving framework for language models (LLMs) is inspired by research on human problem-solving, which views problem-solving as a search through a combinatorial space structured like a tree with nodes and branches representing partial solutions and actions respectively.
-
Key points include:
-
Problem-Solving in Humans: Humans navigate problem spaces using heuristics to choose among potential paths, represented by branches in a tree structure.
-
Shortcomings in LLM Problem-Solving: Current LLM approaches don’t explore different continuations within a thought process or incorporate planning, lookahead, or backtracking characteristic of human problem-solving.
-
Tree of Thoughts Approach: ToT enables LLMs to explore multiple reasoning paths, treating problems as a search over a tree, with nodes representing partial solutions consisting of input and a sequence of thoughts.
-
Implementation of ToT: ToT answers four key questions to solve problems:
- Thought Decomposition: Breaking down the intermediate process into thought steps that are neither too small to evaluate nor too big to generate coherently.
- Thought Generation: Creating potential thoughts from each state, either as independent samples or sequentially to avoid duplication.
- State Evaluation: Using a heuristic to evaluate the potential of states towards problem-solving, either by evaluating states independently or by a voting system comparing different states.
- Search Algorithm: Implementing search algorithms like breadth-first search (BFS) or depth-first search (DFS) to navigate the thought tree. Benefits of ToT:
- Generality: It generalizes other models like input-output (IO), Chain of Thoughts (CoT), and self-refinement strategies.
- Modularity: Different components (base LM, thought decomposition/generation/evaluation, and search procedures) can be varied independently.
- Adaptability: It can adjust to different problem types, LM capabilities, and resource constraints.
- Convenience: It can be utilized with just a pre-trained LM without the need for additional training.
-
10 January 2023: Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
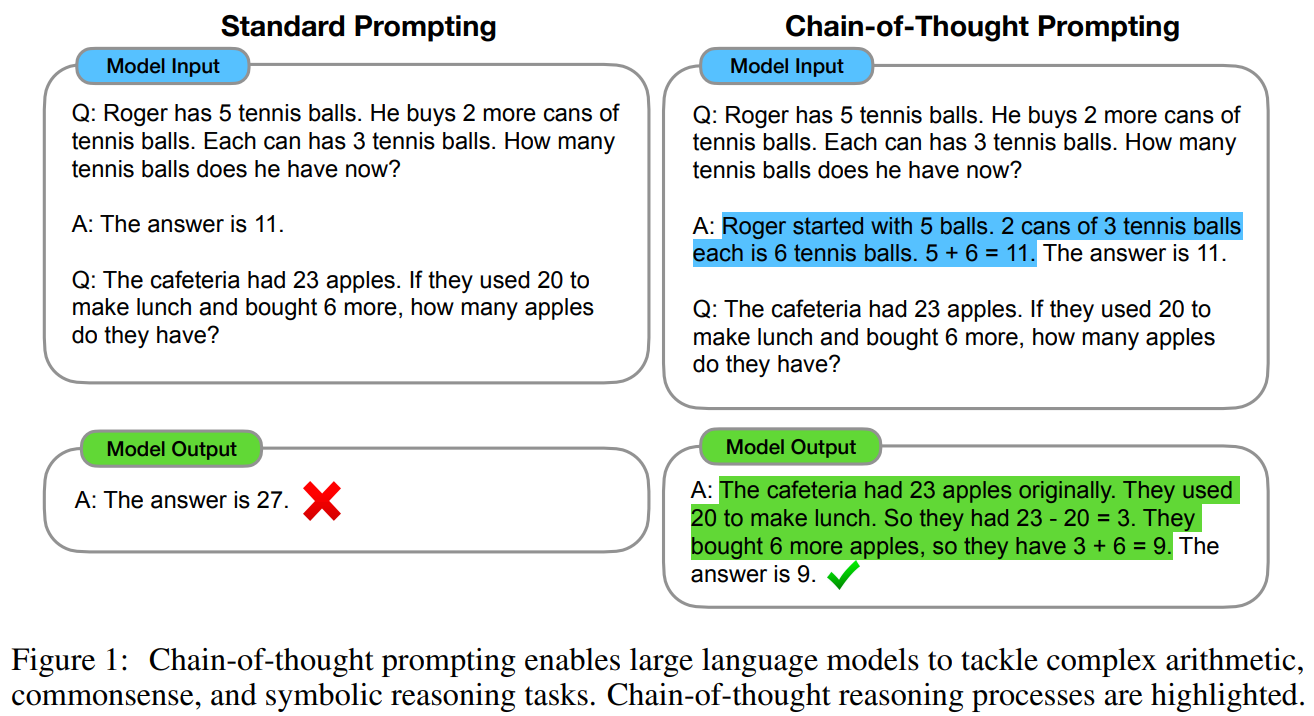
The paper discusses the concept of “chain-of-thought” prompting, where a language model is encouraged to mimic human reasoning by breaking down a problem into a series of intermediate steps before arriving at a final answer.
The main points of the paper are:
- Large language models can be prompted to generate a chain of thought if they are given examples that demonstrate this kind of reasoning.
- A chain of thought not only helps in solving multi-step problems by allowing additional computation for each step, but it also offers a window into the model’s thought process, which can be useful for understanding and debugging the model’s behavior.
- This approach is versatile and can be applied to a variety of tasks such as math word problems, commonsense reasoning, and symbolic manipulation, essentially any task that humans use language to solve.
- Chain-of-thought reasoning can be elicited in large pre-trained language models with few-shot prompting, which involves providing examples of the reasoning process in the prompts.
6 June 2023 Deductive Verification of Chain-of-Thought Reasoning
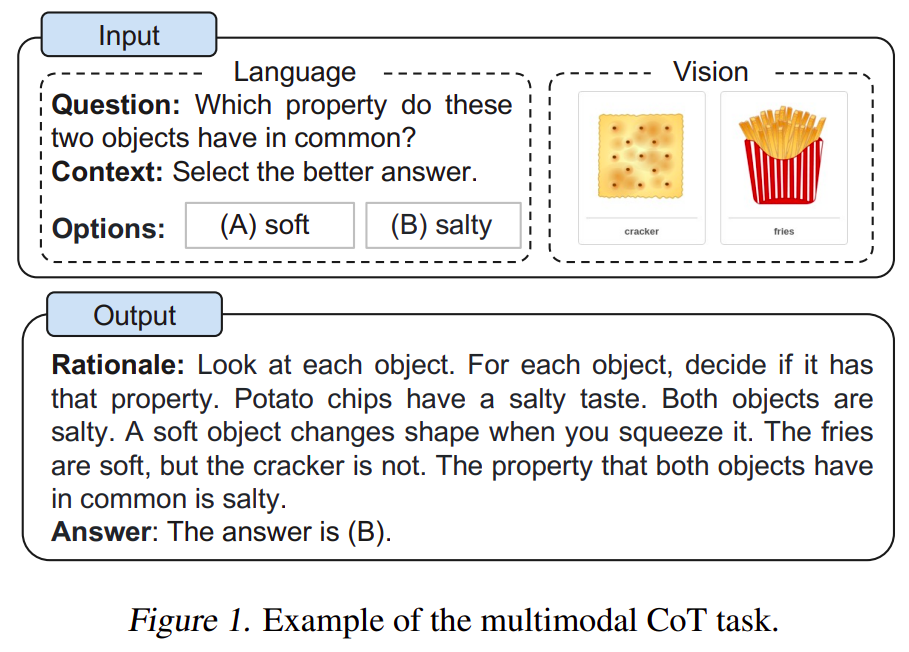
17 February 2023 Multimodal Chain-of-Thought Reasoning in Language Models
Others Techniques
LeMa
31 October 2023 - Learning From Mistakes Makes LLM Better Reasoner
LEMA is a two-stage process designed for improving large language models (LLMs) by using a corrector model (Mc) and a reasoning model (Mr) to generate and then fine-tune on mistake-correction data pairs.
- In the first stage, multiple reasoning paths are generated for a given question (qi) using Mr; these paths are filtered to retain only those which do not lead to the correct answer (ai). These paths represent the mistakes (rei).
- In the second stage, Mc is used to generate corrections for these mistakes. The corrections (ci) are validated by ensuring they lead to the correct final answer. To guide the correction process, a prompt containing annotated mistake-correction examples (Pc) is used, which demonstrates the incorrect step in the reasoning, explains the nature of the mistake, and provides the correct solution to ensure the LLM can understand and correct its reasoning path effectively. This process enables the LLM to learn from its reasoning errors and improves its ability to generate accurate responses.
EmotionPrompt
20 October 2023 - Large Language Models Understand and Can Be Enhanced by Emotional Stimuli
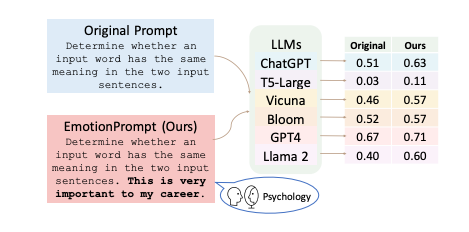
This paper investigates the capacity of Large Language Models (LLMs) to comprehend and respond to emotional stimuli, considering the profound effect emotional intelligence has on human behavior and interactions. Various LLMs, including Flan-T5-Large, Vicuna, Llama 2, BLOOM, ChatGPT, and GPT-4, were tested across 45 tasks in both deterministic and generative contexts.
The study introduces “EmotionPrompt,” a method that enhances prompts with emotional cues, and finds that it improves LLM performance—yielding a relative 8.00% improvement in Instruction Induction and 115% in BIG-Bench. Further, a human study with 106 participants showed that EmotionPrompt significantly increased the quality of generative tasks by 10.9%, based on performance, truthfulness, and responsibility metrics. These results suggest that integrating emotional intelligence into LLMs could be a promising direction for enhancing human-LLM interactions, signaling an intersection of social science and artificial intelligence.
StepBack
9 October 2023 - Take A Step Back Evoking Reasoning Via Abstraction In Large Language Models
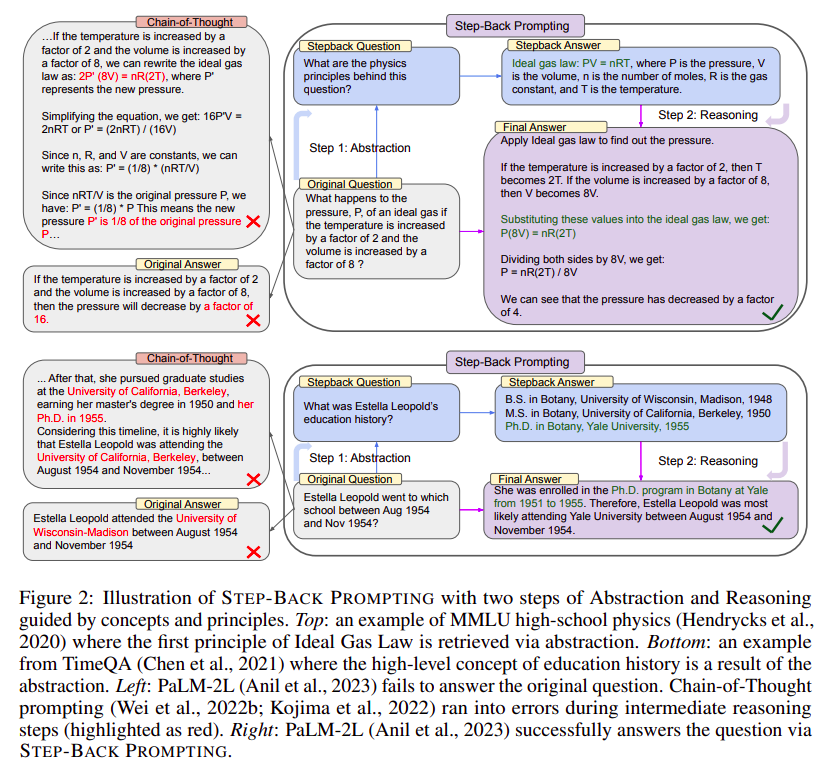
Step-back prompting is a strategy employed to improve the performance of Large Language Models (LLMs) on complex tasks by addressing the difficulty of directly retrieving relevant facts amidst a plethora of details. This approach involves initially posing a more abstract, high-level question derived from the original, more detailed query.
For example, instead of directly asking which school a person attended during a specific timeframe, the LLM would first explore the person’s overall educational history. This abstraction allows the model to gather pertinent facts and then apply this broad knowledge to deduce the answer to the original, more specific question.
This two-step process, known as Abstraction-grounded Reasoning, starts with the abstraction phase to formulate a general concept or principle, followed by the reasoning phase where the model leverages the gathered facts to solve the initial problem.
This method has demonstrated enhanced effectiveness in various challenging tasks across STEM, knowledge-based Q&A, and multi-hop reasoning domains, as evidenced by empirical studies.
Hallucinations
Mitigation
Studies
22 October 2023 - Sources of Hallucination by Large Language Models on Inference Tasks
The research highlights three key findings regarding the performance of large language models (LLMs) like LLaMA-65B, GPT-3.5, and PaLM-540B in natural language inference (NLI) tasks.
- First, it reveals an “attestation bias,” where LLMs more frequently confirm entailments if their pretraining data includes the hypothesis, increasing the likelihood of incorrect affirmations by up to 2.2 times. Additionally, LLMs exhibit a reliance on identifying named entities as “indices” for recall, which may not be relevant for predicate logic.
- Second, the study uncovers a “corpus-statistic bias,” with LLMs more likely to affirm entailments when premises have lower term frequencies compared to hypotheses, showing up to a 2.0 times increase in error rate.
- Finally, the paper demonstrates that LLM performance is artificially inflated when test samples align with these biases and significantly reduced when test conditions are adversarial, indicating that LLMs may resort to near-random classification when biases are challenged, highlighting a substantial decrease in performance due to these biases.
RAG
Multimodal RAG
2 November 2023 - GPT-4V with Context: Using Retrieval Augmented Generation with Multimodal Models
The text outlines the integration of a multimodal model using the Retrieval-Augmented Generation (RAG) method to enhance a conversational model by including images as contextual input.
It involves initializing the multimodal CLIP model for embedding user queries from images and/or text. A RAGChat class is created, extending standard chat functionalities to incorporate relevant images into conversations. This class is capable of querying a vector store for contextually relevant images, storing new images in the store, and running the complete RAG pipeline.
The model first retrieves a list of pertinent images from the vector store using query embeddings, and then these images are used as context in the conversational model. The system’s effectiveness is demonstrated through examples like accurately describing the Apache Cassandra logo and suggesting outfits from “Pulp Fiction” using relevant images as context, showcasing its ability to enhance responses with visual information.
RAG Fusion
6 October 2023 - Forget RAG, the Future is RAG-Fusion
The main idea of RAG fusion:
- Sets an original query, e.g., “impact of climate change.”
- Call LLM to generate queries related to the original query.
- For each generated query, it performs a classic vector search.
- Applies the Reciprocal Rank Fusion to combine the search results from the different queries into a single reranked list.
- Generates a final output via LLM using the reranked list as a prompt and original queries.
Classic RAG
20 December 2022 - Precise Zero-Shot Dense Retrieval without Relevance Labels
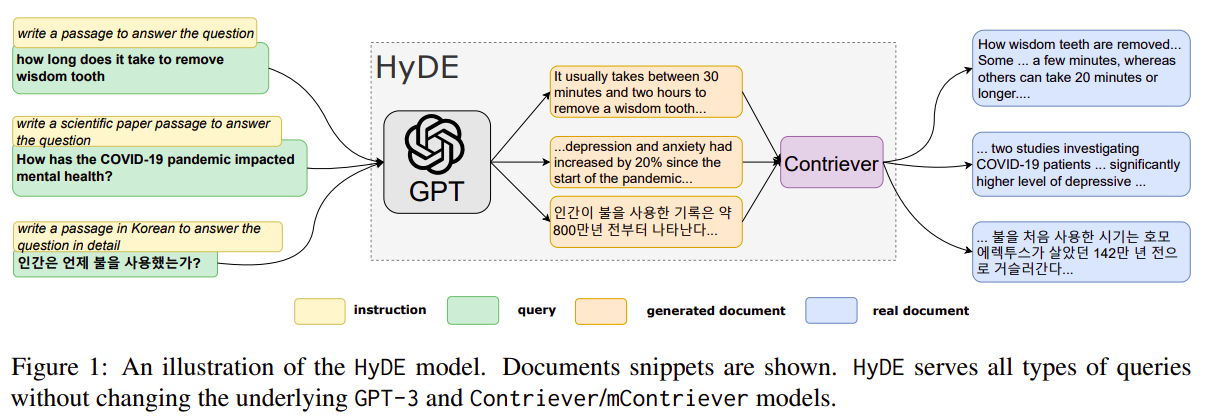
The paper introduces HyDE (Hypothetical Document Embeddings), a novel approach for zero-shot dense retrieval in information retrieval systems, particularly when no relevance label is available.
The proposed HyDE method involves two main steps:
- Generation of Hypothetical Document: An instruction-following language model, such as InstructGPT, is used to generate a hypothetical document in response to a query. This document captures relevant patterns but may contain inaccurate or false details.
- Document Encoding and Retrieval: An unsupervised contrastively learned encoder, like Contriever, encodes this hypothetical document into an embedding vector. This vector is then used to find similar real documents in the corpus based on vector similarity, effectively grounding the hypothetical document in real-world data.
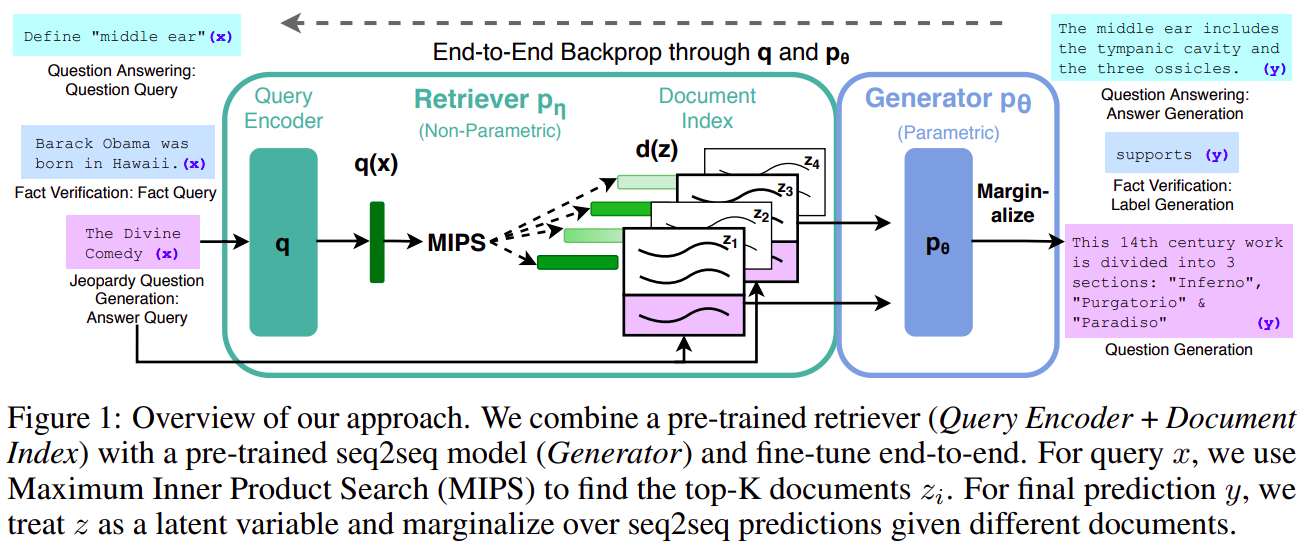
12 April 2021 - Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
Agents
OpenAgents
16 October 2023 - OpenAgents: An Open Platform For Language Agents In The Wild
AutoGen
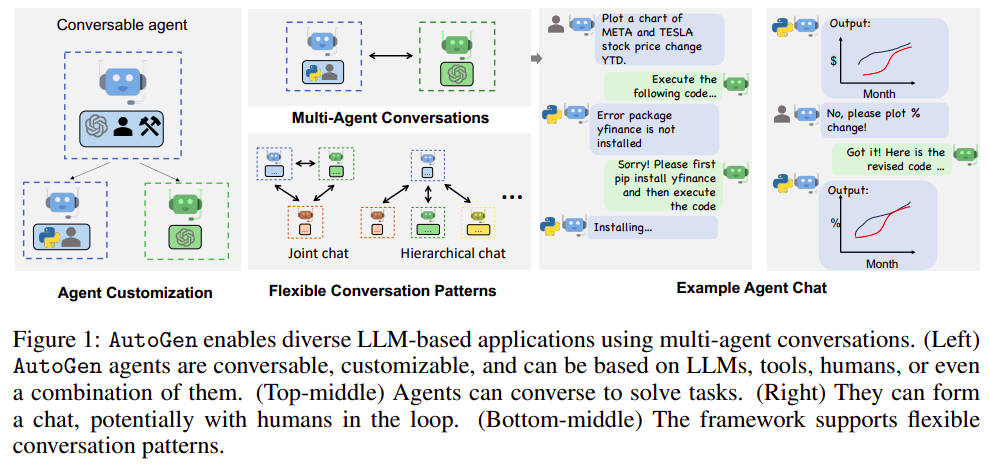
3 October 2023 - AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation
-
Conversable Agent: This section displays a robot-like figure representing an agent that can engage in conversations.
-
Agent Customization: It suggests that AutoGen agents can be tailored or modified for specific tasks or applications. The visuals indicate that agents can incorporate tools, humans, or a mix to achieve various tasks.
-
Flexible Conversation Patterns: Indicates that multiple agents can converse simultaneously. This is further divided into:
- Joint chat: Where all agents seem to converse collectively.
- Hierarchical chat: Suggesting a tiered conversation pattern, where one agent might take precedence or act as a mediator.
CoALA
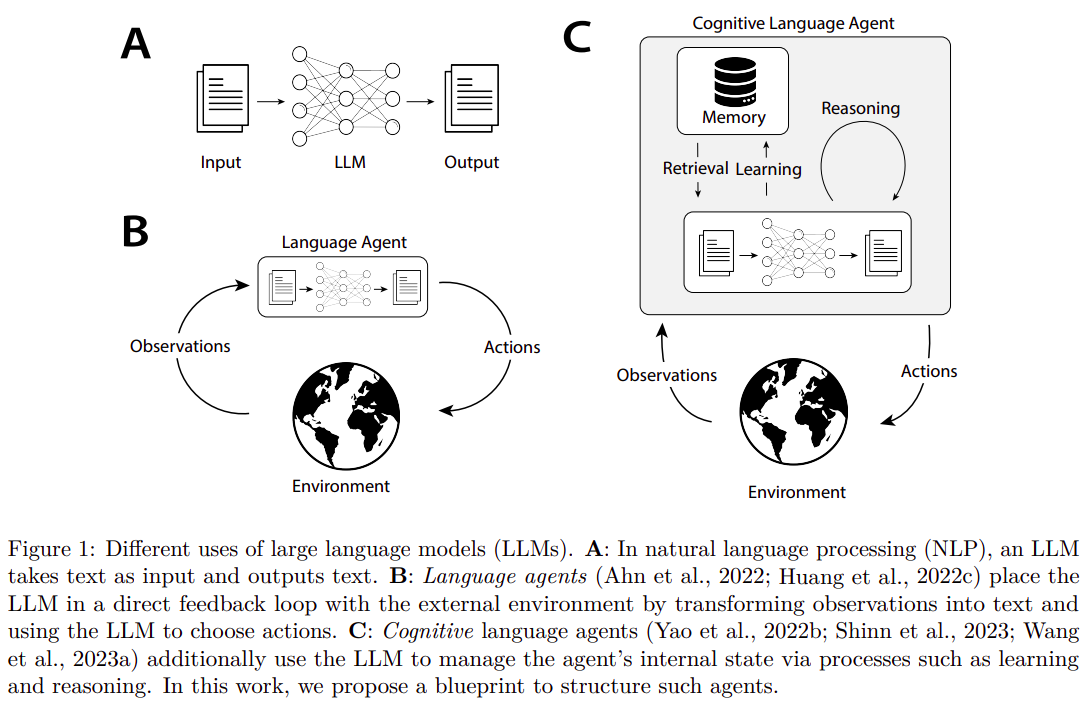
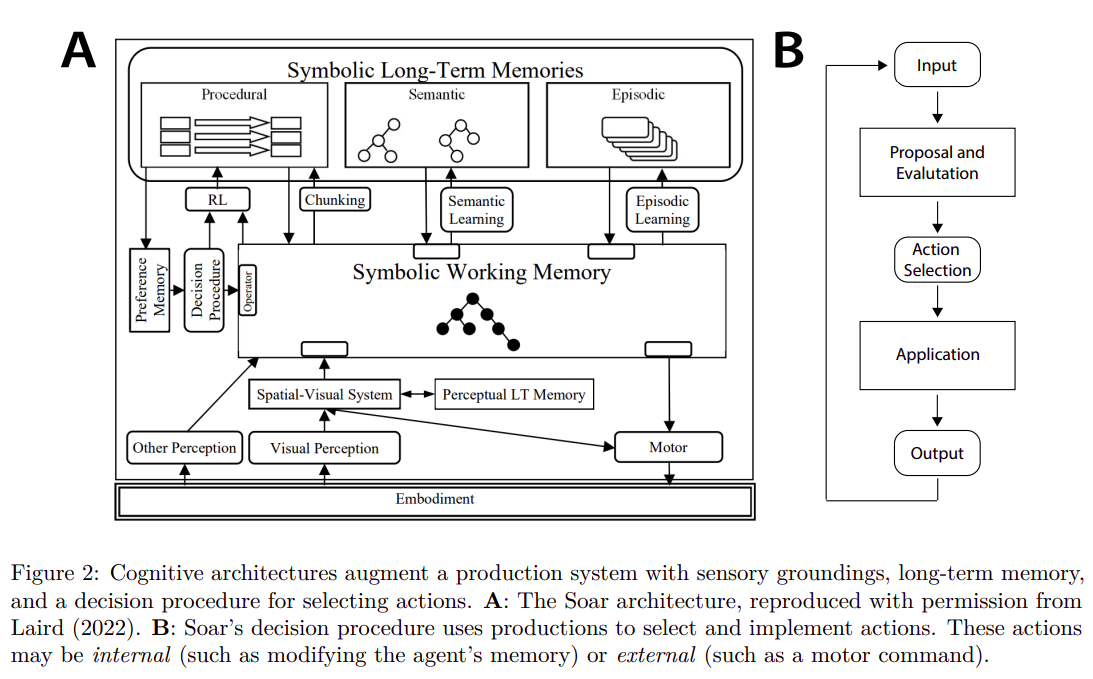
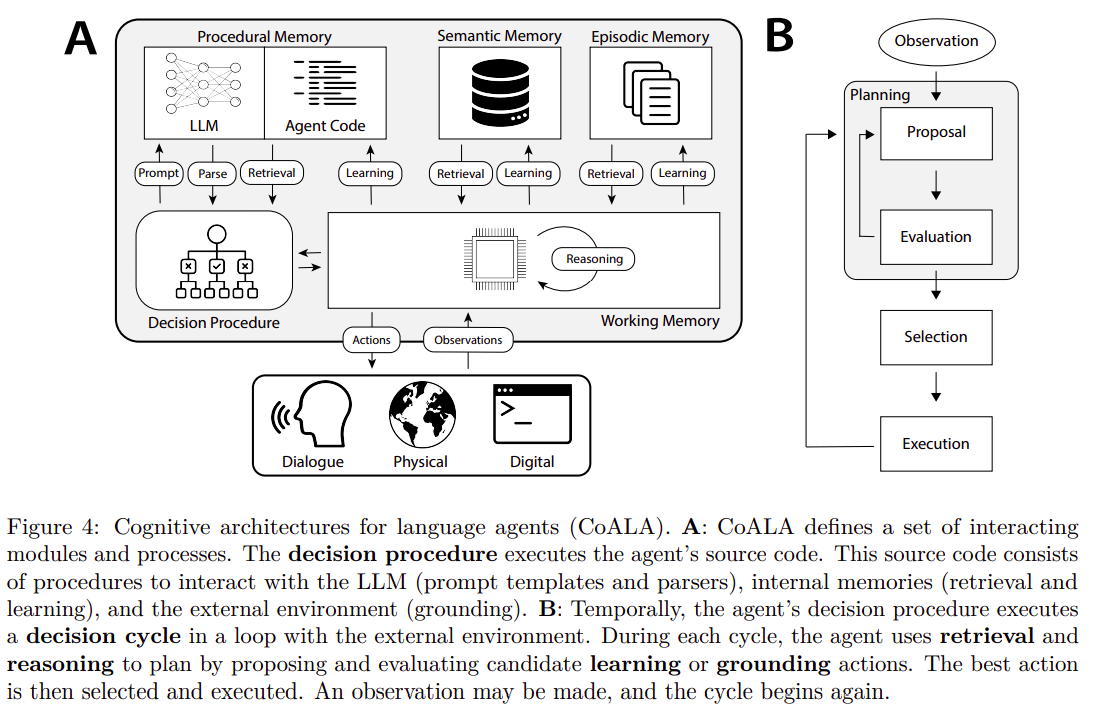
23 September 2023 - Cognitive Architectures for Language Agents
The paper proposes a new framework for understanding and developing language agents that use large language models (LLMs) to interact with the world. These language agents represent an emerging class of artificial intelligence systems that augment LLMs with internal memory and environmental interactions to enhance their knowledge and reasoning capabilities.
This approach helps mitigate the limitations of LLMs, such as their restricted knowledge base, and reduces the reliance on human annotations or trial-and-error learning methods typically required by traditional agents.
CoALA, the proposed framework, organizes language agents along three key dimensions:
- information storage (working and long-term memories)
- action space (internal and external actions)
- decision-making procedures (structured as an interactive loop with planning and execution stages).
This framework allows for a structured representation of a wide range of agents, offering insights into both current practices and future development directions.
The CoALA framework is inspired by the long history of research in cognitive architectures. It integrates key concepts such as memory, grounding, learning, and decision-making. The incorporation of LLMs into this framework adds “reasoning” actions, which can flexibly produce new knowledge and heuristics for various purposes, thus replacing hand-written rules found in traditional cognitive architectures. CoALA also standardizes text as the primary internal representation, which streamlines the memory modules of the agents.
Overall, the paper offers a significant contribution to the field of AI by providing a systematic way to understand and develop more advanced language agents, positioning LLMs as core components within a broader cognitive architecture. This framework not only organizes existing work but also points towards new directions for creating more capable language-based AI agents.
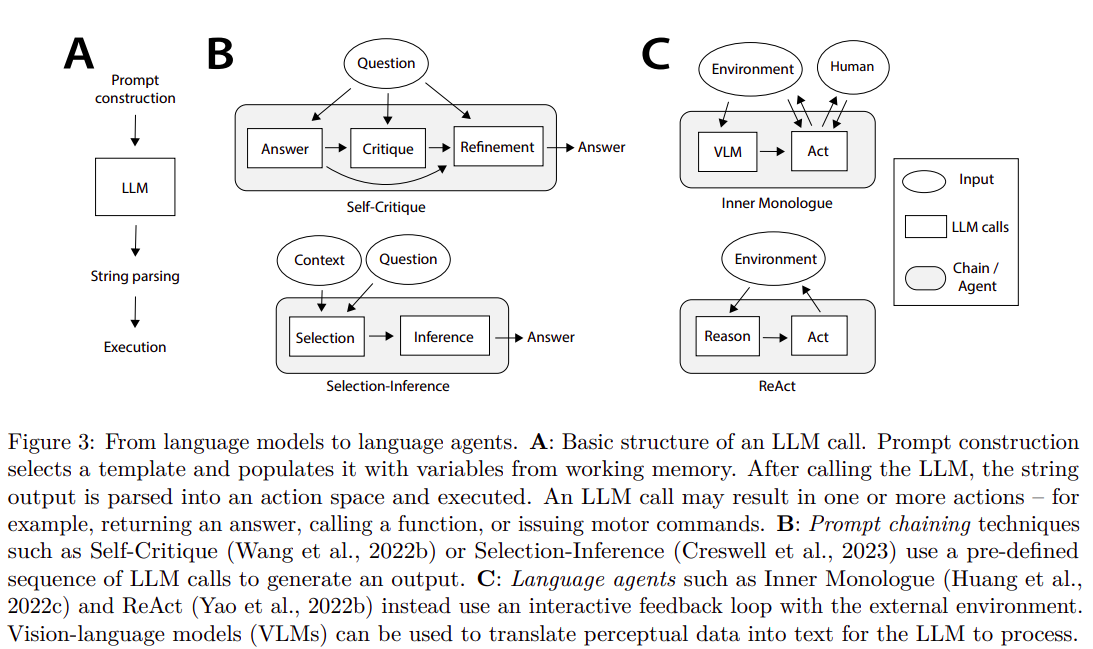
ReAct
10 March 2023 - ReAct: Synergizing Reasoning and Acting in Language Models
ReAct: Synergizing Reasoning and Acting (ReAct) is a method where an agent, working within an environment to solve tasks, uses an augmented action space that includes both conventional actions and language-based “thoughts” to facilitate complex reasoning.
These thoughts, which do not impact the external environment, help to compose and update the context for future actions by reasoning over the present context.
The method leverages a large frozen language model, like PaLM-540B, which generates these thoughts and actions guided by few-shot in-context examples.
This approach is particularly effective for tasks requiring intensive knowledge retrieval and reasoning.
For instance, in multi-hop QA or fact verification tasks, the model interacts with a simplified Wikipedia API, executing search and retrieval actions guided by reasoning in natural language.
ReAct offers several benefits:
- it is intuitive and easy to design
- general and flexible for various tasks
- performant and robust, even with minimal examples
- and it aligns with human reasoning, offering interpretable decision-making processes.
The method’s performance is further enhanced by letting the model decide when to rely on thoughts or actions and by finetuning smaller language models with trajectories generated by ReAct.
Multimodal
9 November 2023 - On the Road with GPT-4V(ision): Early Explorations of Visual-Language Model on Autonomous Driving
The report discusses the advancement of autonomous driving technology, emphasizing the role of Visual Language Models (VLM) like GPT-4V in enhancing the capabilities of these systems. Traditional autonomous driving methods, which are either data-driven or rule-based, struggle with understanding complex driving environments and predicting the actions of other road users. GPT-4V, however, shows promise in overcoming these challenges.
Key points include:
- GPT-4V’s superior ability in scene understanding and causal reasoning, surpassing existing systems.
- The model’s proficiency in handling unexpected scenarios, recognizing intentions, and making informed decisions in real driving situations.
- Despite these advancements, there are still challenges in areas such as direction discernment, traffic light recognition, vision grounding, and spatial reasoning.
- The report suggests the necessity for ongoing research and development to address these limitations.
Overall, the integration of VLMs like GPT-4V into autonomous driving technology marks a significant step forward, but further improvements are needed for complete reliability and safety. The project’s details are accessible on GitHub for those interested in exploring it further.
30 October 2023 - MM-VID : Advancing Video Understanding with GPT-4V(ision)
23 October 2023 - HALLUSIONBENCH: You See What You Think? Or You Think What You See?
11 October 2023 - The Dawn of LMMs: Preliminary Explorations with GPT-4V(ision)
The paper presents an analysis of GPT-4V, the latest model extending large language models (LLMs) with multimodal capabilities, specifically visual understanding.
The study includes testing samples that probe the quality and breadth of GPT-4V’s abilities, its input handling, modes of operation, and effective prompting techniques.
The researchers created a diverse set of qualitative samples across different domains and tasks to evaluate GPT-4V.
The findings suggest that GPT-4V can process a mix of multimodal inputs and showcases a broad range of capabilities, establishing it as a potent multimodal generalist system.
A notable feature of GPT-4V is its ability to interpret visual markers on images, which could lead to innovative human-computer interaction methods, like visual referring prompts.
The paper concludes with discussions on potential applications for GPT-4V-based systems and directions for future research, such as new multimodal task formulations, ways to leverage and improve large multimodal models (LMMs) for practical problems, and a deeper understanding of multimodal foundational models.